Kafka
Before Kafka
- 엔드투엔드 연결 방식의 아키텍쳐였고, 데이터 연동의 복잡성의 증가, 각기 다른 데이터 파이프라인 연결 구조
After Kafka
- 프로듀서/컨슈머 분리, 메시지 데이터 여러 컨슈머에게 허용, 높은 처리량을 위한 메시지 최적화, 스케일 아웃 가능
Kafka broker
- 실행된 카프카 app 서버 중 1대
- 3대 이상의 브로커로 클러스터 구성
- 주키퍼와 연동
- 주키퍼 : 메타데이터(브로커id, 컨트롤러id 등) 저장
- n개 브로커 중 1대는 컨트롤러 기능 수행
- 컨트롤러 : 각 브로커에게 담당 파티션 할당 수행. 브로커 정상 동작 모니터링 관리. 누가 컨트롤러 인지는 주키퍼에 저장.
Record
객체를 프로듀서에서 컨슈머로 전달하기 위해 Kafka 내부에 byte 형태로 저장할 수 있도록 직렬화/역직렬화하여 사용
기본 제공 직렬화 class : StringSerializer, ShortSerializer 등
커스텀 직렬화 class를 통해 Custom Object 직렬화/역직렬화 가능
⚠️ SK 플래닛에서는 Key: NULL, Value: JSON 자체 형식으로 사용
new ProducerRecord<String, String>("topic","key","message");
ConsumerRecords<String, String> records = consumer.poll(1000); for(ConsumerRecord<String,String> record : records) { ... }Topic & Partition
- 메시지 분류 단위
- n개의 파티션 할당 가능
- 각 파티션마다 고유한 오프셋(offset)을 가짐
- 메시지 처리순서는 파티션 별로 유지 관리됨
Producer & Consumer
- 프로듀서는 레코드를 생성하여 브로커로 전송
- 전송된 레코드는 파티션에 신규 오프셋과 함께 기록됨
- 컨슈머는 브로커로부터 레코드를 요청하여 가져감(Polling)
Kafka log and segment
- 실제로 메시지가 저장되는 파일시스템 단위
- 메시지가 저장될때는 세그먼트파일이 열려있음
- 세그먼트는 시간 또는 크기 기준으로 닫힘
- 세그먼트가 닫힌 이후 일정 시간(또는 용량)에 따라 삭제(delete) 또는 압축(compact)
파티션 3개인 토픽과 컨슈머 1대
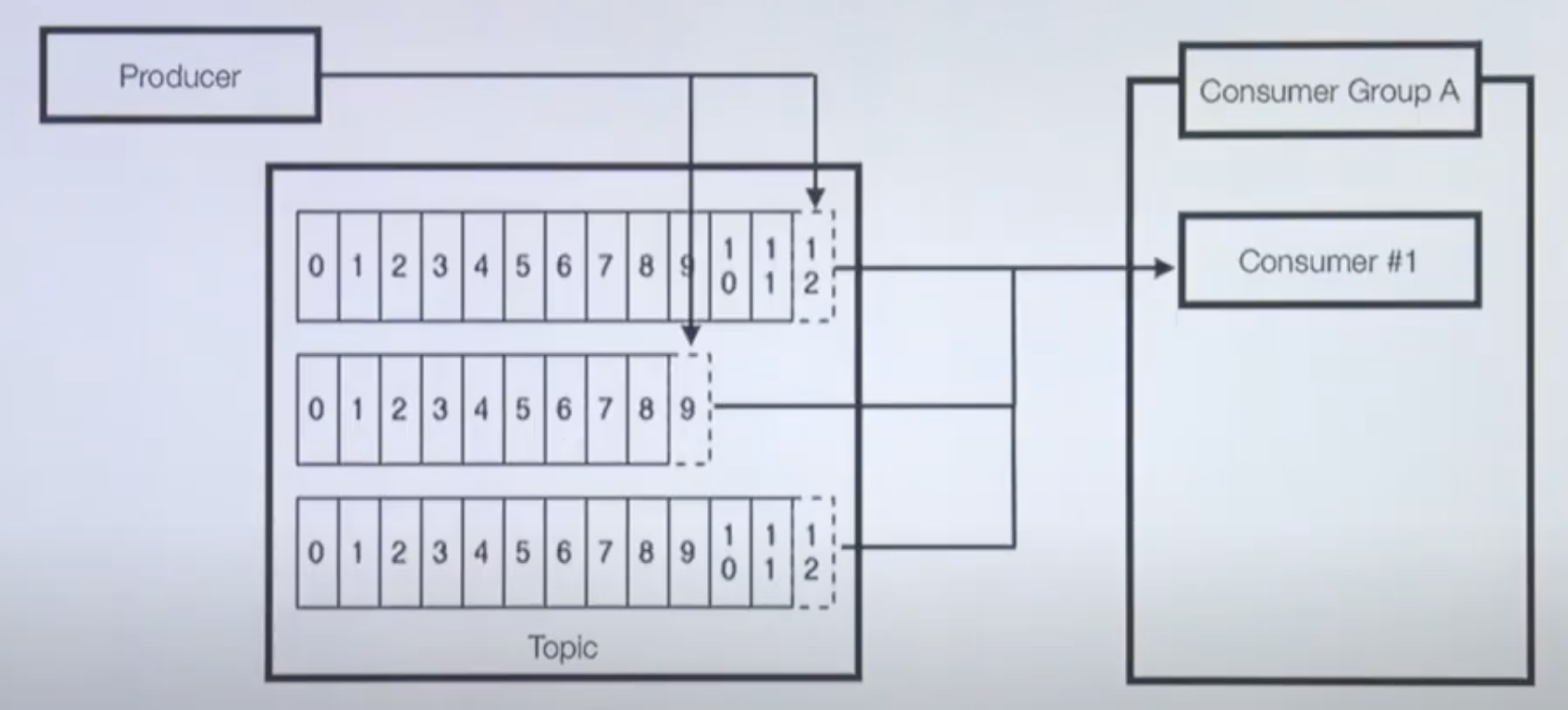
- 파티션이 3개인 토픽
- 1개의 프로듀서가 토픽에 레코드를 보내는 중
- 1개의 컨슈머가 3개의 partition으로부터 polling 중
파티션 3개인 토픽과 컨슈머 3대

- 파티션이 3개인 토픽
- 1개의 프로듀서가 토픽에 레코드를 보내는 중
- 3개의 컨슈머로 이루어진 1개의 컨슈머 그룹이 토픽으로부터 polling 중
파티션이 3개인 토픽과 컨슈머 4대

- 가능한 경우 : 파티션 개수 ≥ 컨슈머 개수
- 불가능한 경우 : 파티션 개수 ≤ 컨슈머 개수
- 남은 컨슈머는 파티션을 할당받지 못하고 대기 중
컨슈머 3대 중 1대 장애 발생
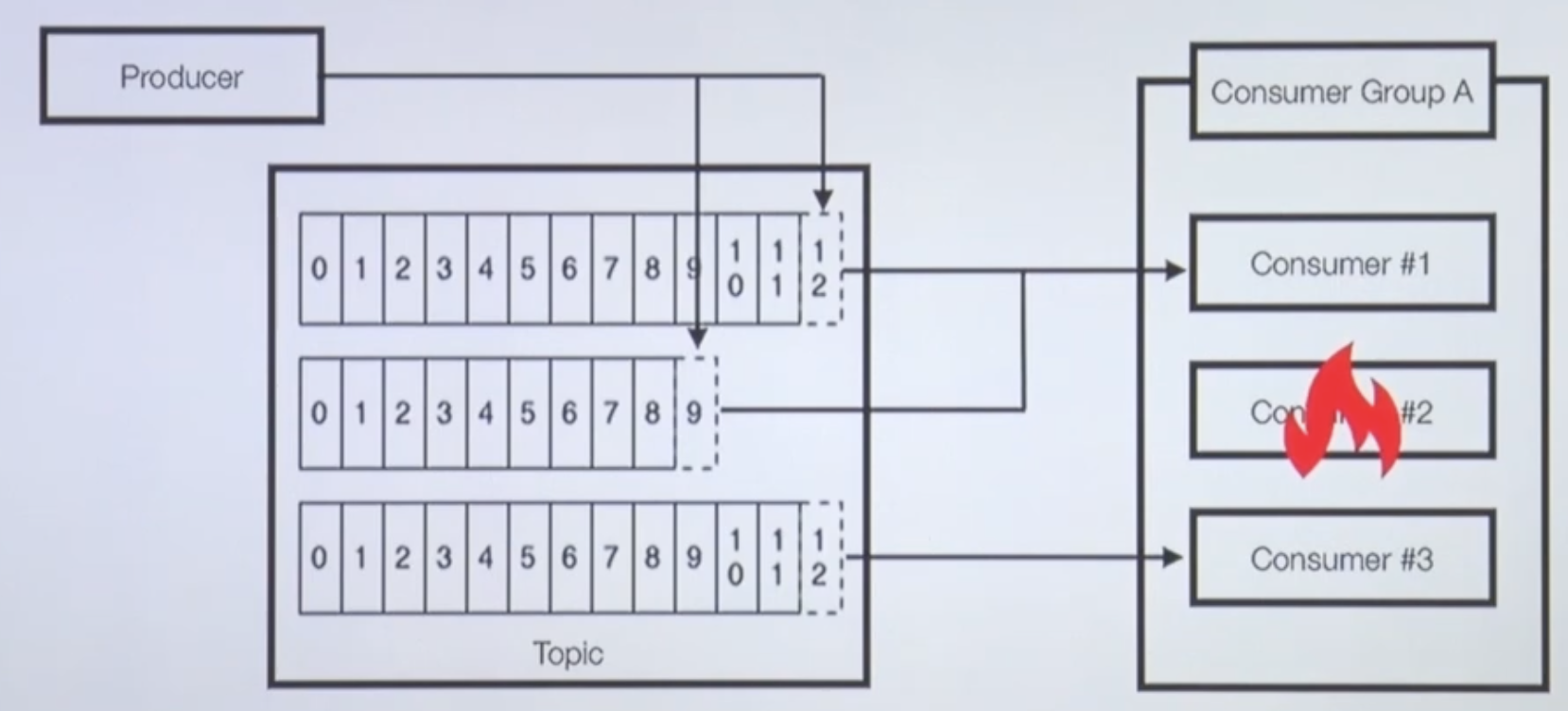
- 컨슈머 중 한개가 장애가 난 경우에 대한 대비 가능
- 리밸런스 발생 : 파티션 컨슈머 할당 재조정
- 나머지 컨슈머가 파티션으로부터 polling 수행
2개 이상의 컨슈머 그룹

- 목적에 따른 컨슈머 그룹을 분리할 수 있음
⚠️장애에 대응하기 위해 재입수(재처리) 목적으로 임시 신규 컨슈머 그룹을 생성하여 사용하기도 함
- 목적에 따른 컨슈머 그룹을 분리할 수 있음
애플리케이션 로그 적재용 컨슈머 그룹 2개

- Application log 적재 상황
- 엘라스틱서치 : 로그 실시간 확인용. 시간순 정렬
- 하둡 : 대용량 데이터 적재, 이전 데이터 확인용
- Application log 적재 상황
컨슈머 그룹 장애에 격리되는 다른 컨슈머 그룹

- 컨슈머 그룹간 간섭(coupling) 줄임
- 하둡에 이슈가 발생하여 컨슈머의 적재지연이 발생하더라도 엘라스틱서치에 적재하는 컨슈머의 동작에는 이슈가 없음.
Broker partition replication

bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic topic_name --partitions 3Broker 1 이슈

- Question : Kafka broker 이슈에 대응하기 위해 사용할 수 있는 방법은?
- Answer : Partition을 다른 Broker에 복제하여 이슈에 대응한다.
1번 Broker에 이슈가 생기면 다른 Broker에 복제된 데이터를 사용한다.

bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic topic_name --partitions 3 --replication-factor 3고가용성을 위한 복제

- 파티션 복제기능으로 데이터 유실 방지
- ⚠️기본 설정으로 —replicator-fator 3으로 운영중
리더 파티션, 팔로워 파티션
- 리더 파티션 : Kafka 클라이언트와 데이터를 주고 받는 역할
- 팔로워 파티션 : 리더 파티션으로부터 레코드를 지속 복제(복제하는데 시간이 걸림).
리더 파티션의 동작이 불가능할 경우 나머지 팔로워 중 1개가 리더로 선출됨
ISR, 리더와 팔로워의 싱크

- 파티션 3개, 레플리케이션이 3개로 이루어진 토픽이 브로커에 할당된 모습
- 특정 파티션의 리더, 팔로워가 레코드가 모두 복제되어 sync가 맞는 상태
⇒ ISR(In-Sync Replica) - ISR이 아닌 상태에서 장애가 나면… ⇒ unclean.leader.election.enable
- false(Default) : 장애 복구시까지 기다린다.
- true : 복제 안된것들 유실시키고 일단 처리한다.
Broker partition replication

- Broker #1 장애 발생 시
- partition #1의 리더가 브로커 2 또는 3 중에 새로 할당
- Kafka 클라이언트는 새로운 파티션 리더와 연동.
- Broker #1 장애 발생 시
Kafka rack-awareness 기능 (고가용성 기능)

- 1개의 Rack에 다수의 브로커를 몰아 넣는 것은 위험
- 다수의 Rack에 분산하여 브로커 옵션(broker.rack) 설정 및 배치
⇒ 파티션 할당 및 레플리케이션 동작 시 특정 브로커에 몰리는 현상 방지
카프카 클러스터에 서버 장애에 대응한 로직이 많은 이유
- 서비스 운영에 있어 장애 허용(Fault-tolerant)은 매우 중요
- 서버의 중단(이슈발생, 재시작) 언제든 발생할 수 있음.
ex) 30대 브로커로 이루어진 카프카 클러스터가 있을때, 1대의 서버가 365일 중 1일 중단이 발생할 가능성이 있다고 가정하면 12.1일(약 2주)에 한번씩 브로커 이슈 발생!!- 일부 서버가 중단되더라도 데이터가 유실되면 안됨
⇒ 안정성이 보장되지 않으면 신뢰도가 하락
- 서비스 운영에 있어 장애 허용(Fault-tolerant)은 매우 중요
참고한 영상
제가 kafka에 대해 공부하면서 참고했던 영상입니다.
'기타' 카테고리의 다른 글
| Kafka 간단한 개념 정리 (2) (3) | 2023.12.22 |
|---|---|
| readme의 트리 구조 폴더링 간단 생성 방법 (0) | 2023.11.09 |

댓글